Robust Landmark-Based Audio Fingerprinting
Note: please see also AUDFPRINT which is a more fully-featured fingerprint tool developed from this codebase.
These routines implement a landmark-based audio fingerprinting system that is very well suited to identifying small, noisy excerpts from a large number of items. It is based on the ideas used in the Shazam music matching service, which can identify seemingly any commercial music tracks from short snippets recorded via cellphones even in very noisy conditions. I don't know if my algorithm is as good as theirs, but the approach, as described in the paper below, certainly seems to work:
Avery Wang "An Industrial-Strength Audio Search Algorithm", Proc. 2003 ISMIR International Symposium on Music Information Retrieval, Baltimore, MD, Oct. 2003. http://www.ee.columbia.edu/~dpwe/papers/Wang03-shazam.pdf
The basic operation of this scheme is that each audio track is analyzed to find prominent onsets concentrated in frequency, since these onsets are most likely to be preserved in noise and distortion. These onsets are formed into pairs, parameterized by the frequencies of the peaks and the time inbetween them. These values are quantized to give a relatively large number of distinct landmark hashes (about 1 million in my implementation). Parameters are tuned to give around 20-50 landmarks per second.
Each reference track is described by the (many hundreds) of landmarks it contains, and the times at which they occur. This information is held in an inverted index, which, for each of the 1 million distinct landmarks, lists the tracks in which they occur (and when they occur in those tracks).
To identify a query, it is similarly converted to landmarks. Then, the database is queried to find all the reference tracks that share landmarks with the queries, and the relative time differences between where they occur in the query and where they occur in the reference tracks. Once a sufficient number of landmarks have been identified as coming from the same reference track, with the same relative timing, a match can be confidently declared. Normally, a small number of matches (e.g. 5) is sufficient to declare a match, since chance matches are very unlikely.
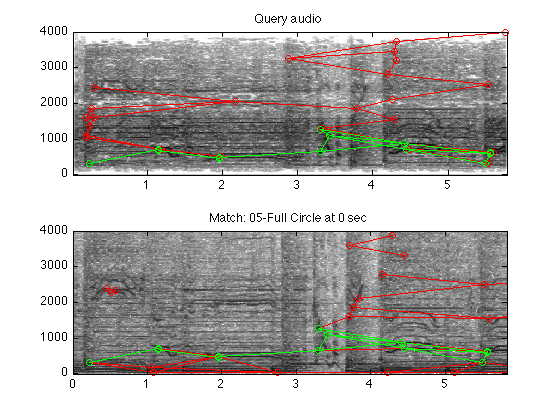
The beauty, and robustness, of this approach is that only a few of the maxima (or landmarks) have to be the same in the refererence and query examples to allow a match. If the query example is noisy, or filtered strangely, or truncated, there's still a good chance that enough of the hashed landmarks will match to work. In the examples below, a 5 second excerpt recorded from a very low-quality playback is successfully matched.
Contents
Example use
In the example below, we'll load a small database of audio tracks over the internet. You will need to have the latest version of my mp3read installed, which supports reading files from URLs. See http://labrosa.ee.columbia.edu/matlab/mp3read.html . myls also relies on having curl available to work (should be fine on Linux/Mac; if you want to run it on Windows, you can download a version of curl from http://curl.haxx.se/download.html , but you'll have to modify myls.m to make it invoke it correctly).
% Get the list of reference tracks to add (URLs in this case, but % filenames work too) tks= myls(['http://labrosa.ee.columbia.edu/~dpwe/tmp/Nine_Lives/*.mp3']); % Initialize the hash table database array clear_hashtable % Calculate the landmark hashes for each reference track and store % it in the array (takes a few seconds per track). add_tracks(tks); % Load a query waveform (recorded from playback on a laptop) [dt,srt] = mp3read('Q-full-circle.mp3'); % Run the query R = match_query(dt,srt); % R returns all the matches, sorted by match quality. Each row % describes a match with three numbers: the index of the item in % the database that matches, the number of matching hash landmarks, % and the time offset (in 32ms steps) between the beggining of the % reference track and the beggining of the query audio. R(1,:) % 5 18 1 18 means tks{5} was matched with 18 matching landmarks, at a % time skew of 1 frame (query starts ~ 0.032s after beginning of % reference track), and a total of 18 hashes matched that track at % any time skew (meaning that in this case all the matching hashes % had the same time skew of 1). % % Plot the matches illustrate_match(dt,srt,tks); colormap(1-gray) % This re-runs the match, then plots spectrograms of both query and % the matching part of the reference, with the landmark pairs % plotted on top in red, and the matching landmarks plotted in % green.
Max entries per hash = 20
Target density = 10 hashes/sec
Adding #1 http://labrosa.ee.columbia.edu/~dpwe/tmp/Nine_Lives/01-Nine_Lives.mp3 ...
Adding #2 http://labrosa.ee.columbia.edu/~dpwe/tmp/Nine_Lives/02-Falling_In_Love.mp3 ...
Adding #3 http://labrosa.ee.columbia.edu/~dpwe/tmp/Nine_Lives/03-Hole_In_My_Soul.mp3 ...
Adding #4 http://labrosa.ee.columbia.edu/~dpwe/tmp/Nine_Lives/04-Taste_Of_India.mp3 ...
Adding #5 http://labrosa.ee.columbia.edu/~dpwe/tmp/Nine_Lives/05-Full_Circle.mp3 ...
Adding #6 http://labrosa.ee.columbia.edu/~dpwe/tmp/Nine_Lives/06-Something_s_Gotta_Give.mp3 ...
Adding #7 http://labrosa.ee.columbia.edu/~dpwe/tmp/Nine_Lives/07-Ain_t_That_A_Bitch.mp3 ...
Adding #8 http://labrosa.ee.columbia.edu/~dpwe/tmp/Nine_Lives/08-The_Farm.mp3 ...
Adding #9 http://labrosa.ee.columbia.edu/~dpwe/tmp/Nine_Lives/09-Crash.mp3 ...
Adding #10 http://labrosa.ee.columbia.edu/~dpwe/tmp/Nine_Lives/10-Kiss_Your_Past_Good-bye.mp3 ...
Adding #11 http://labrosa.ee.columbia.edu/~dpwe/tmp/Nine_Lives/11-Pink.mp3 ...
Adding #12 http://labrosa.ee.columbia.edu/~dpwe/tmp/Nine_Lives/12-Attitude_Adjustment.mp3 ...
Adding #13 http://labrosa.ee.columbia.edu/~dpwe/tmp/Nine_Lives/13-Fallen_Angels.mp3 ...
added 13 tracks (130 secs, 1194 hashes, 9.1846 hashes/sec)
landmarks 371 -> 306 hashes
ans =
5 17 0 17
landmarks 371 -> 306 hashes
Implementation notes
The main work in finding the landmarks is done by find_landmarks. This contains a number of parameters which can be tuned to control the density of landmarks. In general, denser landmarks result in more robust matching (since there are more opportunities to match), but greater load on the database.
The scheme relies on just a few landmarks being common to both query and reference items. The greater the density of landmarks, the more like this is to occur (meaning that shorter and noisier queries can be tolerated), but the greater the load on the database holding the hashes.
The factors influencing the number of landmarks returned are:
1. The number of local maxima found, which in turn depends on the spreading width applied to the masking skirt from each found peak, the decay rate of the masking skirt behind each peak, and the high-pass filter applied to the log-magnitude envelope.
2. The number of landmark pairs made with each peak. All maxes within a "target region" following the seed max are made into pairs, so the larger this region is (in time and frequency), the more maxes there will be. The target region is defined by a freqency half-width, and a time duration.
Landmarks, which are 4-tuples of start time, start frequency, end frequency, and time difference, are converted into hashes with a start time and a 20 bit value describing the two frequencies and time difference, by landmark2hash. hash2landmark undoes this quantization.
The matching relies on the "inverted index" hash table, implemented by clear_hashtable, record_hashes, and get_hash_hits. Currently, it's implemented as a single Matlab array, HashTable, stored in a global of 20 x 10^20 uint32s (about 80MB of core). This can record just 20 occurrences of each landmark hash, but as the reference database grows, this may fill up. You can change the size it is initialized to in clear_hashtable.m, but really it should be replaced with a real key/value database system.
Because the track IDs are stored in just 18 bits of the uint32, we can only handle 256k unique tracks in this implementation. Actually, I've only tried it with up to a few thousand.
Other functions included are add_tracks, which simply ties together find_landmarks, landmarks2hash, and save_hashes to enter a new reference track into the database, match_query, which extracts landmarks from a query audio and matches them against the reference database to returned ranked matches, show_landmarks, a utility to plot the actual landmarks on top of the spectrogram of a sound, and illustrate_match, which uses match_query and show_landmarks to show exactly which landmarks matched for a particular query's top match. Utility function myls is used by this demo script, demo_fingerprint to build a list of files, including possibly over http.
Also included are gen_random_queries to generate random queries of a certain length from a list of tracks (possibly adding noise), eval_fprint to query the fingerprinter with a cell array of query waveforms such as gen_random_queries produces, and addprefixsuffix which is used to construct a cell array list of full file names from a cell array of unique ID strings.
For Windows Users
Robert Macrae of C4DM Queen Mary Univ. London sent me some notes on running this code under Windows.
For Octave Users
Joren Six has a nice page on Porting this code to Octave.
See also AUDFPRINT Compiled Binary
To make it easier to use in some large-scale experiments, I rewrote this code to function as a compiled Matlab stand-alone executable. See the AUDFPRINT page for more details.
Download
You can download all the code and data for these examples here: fingerprint.tgz. For the demo code above, you will also need mp3 read/write.
Referencing
If you use this code in your research and you want to make a reference to where you got it, you can use the following citation:
D. Ellis (2009), "Robust Landmark-Based Audio Fingerprinting", web resource, available: http://labrosa.ee.columbia.edu/matlab/fingerprint/ .
Acknowledgment
This material is based in part upon work supported by the National Science Foundation under Grant No. IIS-0713334. Any opinions, findings and conclusions or recomendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation (NSF).
Last updated: $Date: 2012/05/14 19:45:56 $ Dan Ellis dpwe@ee.columbia.edu